
Deep Dive: The Transaction Foundation Models


We are observing a structural re-architecture of the financial internet. The legacy stack, composed of siloed rule engines, task-specific machine learning models, and human-centric interfaces, is being replaced. We are moving toward a unified paradigm where self-supervised foundation models act as the core operating system for banking and payments. This is a move from information exchange to value exchange. The data suggests that we are witnessing the death of the manual rule engine and the birth of the behavioral embedding as the primary unit of fintech utility.
This deep dive analyzes the technical transition from Gradient Boosted Decision Trees (GBDTs) to Transformer-based foundation models. I will examine the implementation of these systems at Revolut, PayPal, Stripe, and Plaid. I will also detail the infrastructure requirements, the economics of token inference, and the protocol layer defining how AI agents will transact in a zero-trust environment.
The failure of task-specific architectures
For decades, the financial industry relied on Gradient Boosted Decision Trees (GBDTs) like XGBoost and LightGBM. These models were fast, interpretable, and effective for tabular data. However, I believe they reached a ceiling because they depend on human-engineered features. A data scientist had to manually define what constituted a suspicious transaction velocity or a risky credit profile, and this created a bottleneck. Every new product required a new pipeline, a new set of labels, and a new round of feature engineering.
The performance data from Revolut and Plaid indicate that general-purpose foundation models outperform these task-specific models across the board. When a model learns the underlying grammar of transactions through self-supervision, it identifies signals that humans miss.
Relative performance improvements of foundation models
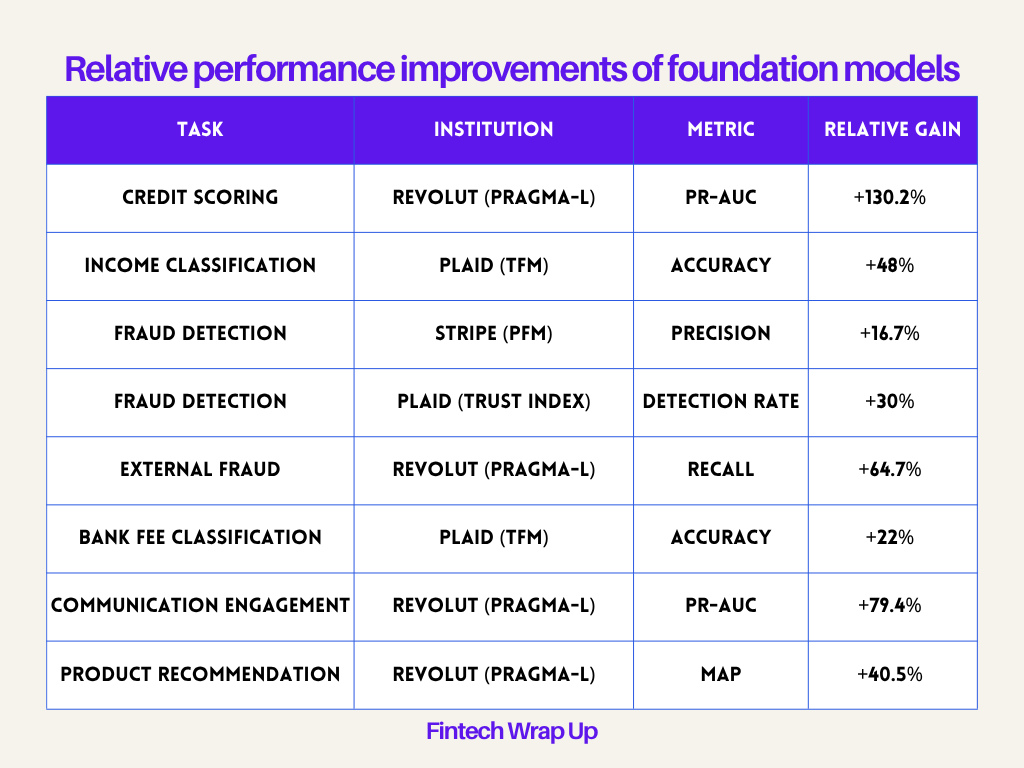
Revolut’s PRAGMA
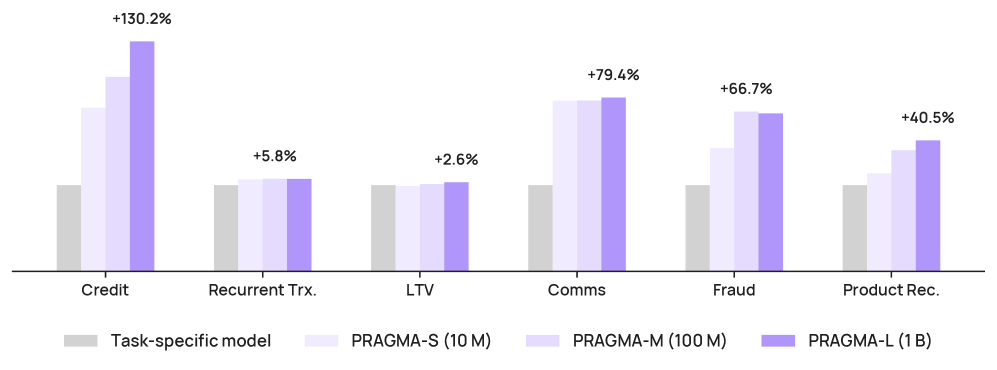
Revolut’s PRAGMA (PRe-trained Banking Foundation Model) is a family of encoder-style models scaling from 10 million to 1 billion parameters. This is the largest published encoder backbone for consumer banking event sequences. PRAGMA treats transactions as part of a multi-source sequence that includes app navigation, communications, and profile state rather than isolated events.
The two-branch encoder architecture
The model uses a two-branch design to handle the heterogeneity of banking data, and I think this is the correct architectural choice for finance. One branch focuses on the profile state: static or slowly changing attributes like account tenure, plan type, and service region. The second branch processes the event history: dynamic sequences of transactions and app interactions.
These branches are fused by a history encoder. This allows the model to contextualize a specific transaction not just by the events that preceded it, but by the user’s overall state. If a user has been a “Metal” plan member for five years, a high-value purchase carries a different risk profile than it does for a new user on a “Standard” plan.
Percentile-based tokenization
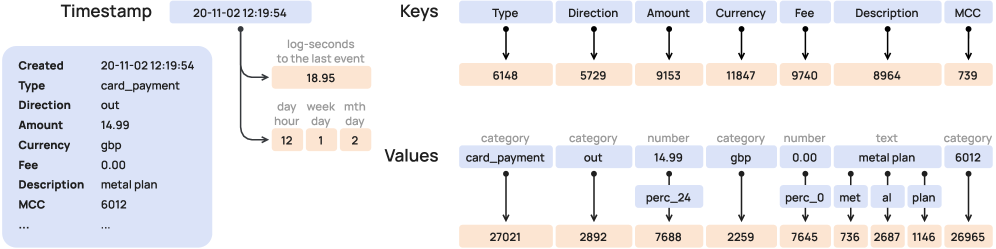
I believe the most important innovation in PRAGMA is its approach to numerical data. Standard LLMs split numbers into digits. I think this is a mistake for financial reasoning because it discards magnitude and ordering. PRAGMA maps numerical values to percentile buckets.
Keep reading with a 7-day free trial
Subscribe to Fintech Wrap Up to keep reading this post and get 7 days of free access to the full post archives.